1.本发明涉及人工智能安全技术领域,具体涉及一种具有听觉高保真度特点的语音对抗样本修复方法。
背景技术:
2.近年来,语音识别对抗攻击开始成为人工智能一个新的研究热点,其通过在输入音频数据中添加人类难以察觉的微弱噪声就能诱导语音识别算法产生错误识别结果。面向语音对抗攻击威胁,国内外学者积极探索人工智能算法安全防御技术。主要的防御方法分为三类,一是通过对抗样本对训练数据集进行扩充进而进行对抗训练,提高智能算法的鲁棒性,这种方法需要产生大量对抗样本并改变原智能算法参数;二是对抗样本检测技术,通过对抗样本检测算法识别输入中的对抗样本,这种方法仅仅可以发现对抗攻击行为但是无法对其进行有效响应;三是对抗样本修复,通过对抗噪声过滤,拟制对抗攻击效果,进而保证原智能算法正确识别。因此,研究对抗样本修复技术对语音识别算法安全可靠应用具有重大现实意义。
3.浙江工业大学在其申请的专利
″
面向语音识别系统黑盒攻击模型的防御方法及防御装置
″
(专利申请号:201911031043.5,公开号:cn110992934a)中提出了一种针对语音识别系统黑盒攻击模型的防御方法。该防御方法首先对原始音频添加模拟环境噪声,模拟现实场景下的语音输入情况,随机添加噪声后形成初代对抗样本,通过遗传算法和梯度估计对对抗样本进行优化,获得精确对抗样本,然后将原始音频文件和对抗样本混合,作为对抗训练的训练数据集,对模型进行再训练,提高了模型对对抗样本的识别准确率,从而提高了模型对于对抗攻击的鲁棒性。但是,该方法仍存在的不足之处是:需要产生大量对抗样本,且仅使用一种类型的对抗样本进行对抗训练对其他攻击方法的防御效果不佳;需要对原语音识别算法进行二次训练,在实际应用中具有局限性。
4.北京邮电大学在其申请的专利
″
基于语音增强算法的对抗样本攻击防御方法及装置
″
(专利申请号:202010206879.0,公开号:cn111564154a)中提出了一种基于语音增强算法的对抗样本攻击防御方法。该方法首先获取待识别语音样本的频谱特征,根据待识别语音样本的频谱特征,通过基于连续最小值跟踪的谱减法与结合语音存在概率的对数最小均方误差算法mmse算法对待识别语音样本进行噪声频谱的计算,并利用计算得到的估计噪声频谱对待识别语音样本进行去噪,得到去噪后的语音样本,然后通过预先训练的语音识别模型对去噪后的语音样本进行识别。该方法可以增加语音识别准确率,提高防御对抗样本攻击的效果。但是,该方法仍存在的不足之处是:该方法本质是一种传统的通用降噪算法,没有针对对抗样本噪声进行针对性改进,防御成功率不高。
技术实现要素:
5.(一)要解决的技术问题
6.本发明要解决的技术问题是:如何设计一种具有听觉高保真度特点的语音对抗样
本修复方法,在保证对干净样本压缩重构后的音频样本与原始样本在听觉感知无较大差异的情况下,又能较好抑制对抗样本攻击效果。
7.(二)技术方案
8.为了解决上述技术问题,本发明提供了一种具有听觉高保真度特点的语音对抗样本修复方法,包括以下步骤:
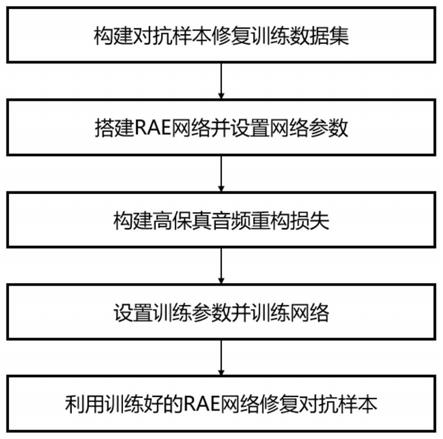
9.(1)构建对抗样本修复训练数据集;
10.(2)搭建rae网络并设置网络结构参数;
11.(3)构建高保真音频重构损失;
12.(4)基于步骤1、步骤2、步骤3设置训练参数并训练rae网络;
13.(5)利用训练好的rae网络修复对抗样本。
14.优选地,步骤1中,采集n条原始音频数据,求取音频数据最大序列长度,将每一条音频数据均补零至最大长度,得到所述对抗样本修复训练数据集。
15.优选地,步骤2包括:
16.(2a)设置网络结构参数,包括输入层、基于bilstm网络的编码器隐藏层、隐变量层、基于bilstm网络的解码器隐藏层、输出层;
17.(2b)结合bilstm网络与ae网络的结构特点搭建rae网络,rae网络的结构中,依次为:输入层
→
基于bilstm网络的编码器隐藏层
→
隐变量层
→
基于bilstm网络的解码器隐藏层
→
输出层,从而得到初始rae网络。
18.优选地,步骤3包括:
19.(3a)利用输入与重构的音频样本,按照公式计算均方误差,其中,l为音频长度,x
t
表示时刻t的原始数据,表示时刻t的重构数据;
20.(3b)利用输入音频样本,按照公式计算每一个时刻音频数据的重构误差权重,其中,x
t2
表示时刻t的语音信号强度,权值w随着x
t2
的增大而减小,λ>0,为尺度参数,λ越大,权值w随x
t2
的增大而减小得越快;
21.(3c)将所述均方误差与重构误差权重对应相乘,即按照公式计算得到高保真音频重构损失。
22.优选地,由公式表达的高保真音频重构损失函数是一种自适应加权均方误差损失函数,允许在语音信号强度大的地方产生大的重构误差,在语音信号强度小的地方限制误差。
23.优选地,步骤4包括:
24.(4a)设置训练参数,包括迭代轮次t、小批量尺寸s以及学习率η,并选择优化算法,优化算法是指基于1阶梯度的优化算法;
25.(4b)读取所述对抗样本修复训练数据集,进行将原始音频数据集划分为个
小批量数据集的预处理操作,得到预处理后的对抗样本修复训练数据集;表示向上取整;
26.(4c)利用预处理后的对抗样本修复训练数据集,采用所选择的优化算法,根据所述高保真音频重构损失与学习率η进行反向传播训练初始rae网络:将个小批量数据依次输入到rae网络中,利用所选择的优化算法,按照前向传播、反向传播、权重更新的顺序,重复t轮,共计迭代次后停止训练,得到训练好的rae网络。
27.优选地,所述优化算法为adam算法。
28.优选地,步骤5包括:
29.(5a)读取对抗样本,利用训练好的rae网络模型修复所述对抗样本,输出修复后的样本;所述对抗样本是通过语音对抗样本生成算法所生成的一种音频数据,其通过在干净样本上添加扰动而诱导语音识别模型产生错误识别结果;
30.(5b)将对抗样本与修复后的样本输入语音识别模型,观察对抗样本修复效果,若对抗样本修复效果表示修复后的样本识别结果正确,则修复成功,否则,修复失败。
31.优选地,所述对抗样本修复效果具体包括两方面内容,一方面观察对抗样本与修复后的样本的声谱差异,另一方面观察对抗样本与修复后的样本输入到语音识别模型识别后的结果。
32.本发明还提供了一种所述方法在人工智能安全技术领域中的应用。
33.(三)有益效果
34.本发明利用rae网络与高保真音频重构损失对对抗样本进行修复,在保证对干净样本压缩重构后的音频样本与原始样本在听觉感知无较大差异的情况下,又能较好抑制对抗样本攻击效果。
35.本发明高保真音频损失重构策略是指由于对抗样本的构建就是基于信号方差大的区域添加微弱扰动,继而使识别模型出现错误判断的理论。基于编码-解码的方式使音频通过降维到升维的过程中,利用权重对损失函数的控制,动态地让信号强度小的区域不允许出现误差,让信号强度大的区域允许出现合理的误差来丢弃原本不属于信号的扰动。
36.本发明经实验验证,无论黑盒/白盒环境下生成的语音对抗样本,本算法生成的修复样本可在自动语音指令识别系统上的识别结果为给定的任意指令,与其他语音对抗样本修复算法相比,在对抗样本识别结果和原始标签错误率相同的情况下,本方法修复成功率更高,从听觉上也具备保真性。
附图说明
37.图1是本发明的方法流程图;
38.图2是本发明的rae网络结构图;
39.图3是原始音频声谱图;
40.图4是对抗样本声谱图;
41.图5是本发明生成的音频修复样本声谱图。
具体实施方式
42.为使本发明的目的、内容、和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
43.本发明提出了一种具有听觉高保真度特点的语音对抗样本修复方法,利用rae(recurrent autoencoder,循环自动编码器)网络与高保真音频重构损失对对抗样本进行修复,在保证对干净样本压缩重构后的音频样本与原始样本在听觉感知无较大差异的情况下,又能较好抑制对抗样本攻击效果。
44.该方法利用原始音频构建具有高保真特点的变分自编码器,让对抗样本在压缩与重构的过程中,起到抑制对抗攻击效果的目的,其次,利用高保真音频重构损失增强输入音频与重构音频之间的听觉相似度,
45.本发明整体流程如图1所示,包括以下步骤:
46.步骤1,构建对抗样本修复训练数据集。
47.采集原始音频数据共4000条,音频数据的格式为“.wav”格式,音频采样频率为16khz,音频采样时长小于等于1秒;求取音频数据最大序列长度为16000,将每一条音频数据均补零至最大长度,得到对抗样本修复训练数据集,该数据集包括down、go、left、off、on、right、stop、up构成的共八类英文音频数据。
48.步骤2,参考图2,搭建rae网络并设置网络参数。
49.设置网络结构参数,其中输入层维度为100
×
160,将每条音频数据分为100段,每段160帧,基于bilstm(bi-directional long short-term memory,双向长短期记忆)网络的编码器隐藏层大小为64、隐变量层大小为64、基于bilstm网络的解码器隐藏层大小为64、输出层维度为100
×
160。bilstm网络是指双向长短期记忆网络,是一个两层循环神经网络,即当前的输出不仅受到之前状态的影响,而且会受到未来状态的影响,对于每一时刻t,输入会同时提供两个相反的循环神经网络来共同决定输出。
50.结合bilstm两层循环神经网络与ae自编码器无监督学习的五层网络结构特点搭建rae网络,其结构依次为:输入层
→
基于bilstm网络的编码器隐藏层
→
隐变量层
→
基于bilstm网络的解码器隐藏层
→
输出层,得到初始rae网络。ae网络是指自编码器网络,是一种无监督学习模型,包括从输入层到隐藏层的原始数据x的编码过程,以及从隐藏层到输出层的解码过程,则原始数据x与重构数据之间的距离即为数据x的误差损失。rae网络即rnn-ae网络,是一种循环自编码器网络,在编码器和解码器中使用bilstm网络,将原始音频数据输入编码器中,通过bilstm网络的学习,编码器当前时刻的输出z
t
受到当前时刻状态h
t
与未来时刻状态c
t
的共同影响,编码器最终时刻的输出z
t
进入解码器中,再次通过bilstm网络的学习,解码器当前时刻的输出z
t
受到当前时刻状态h
t
与未来时刻状态c
t
的共同影响,最终解码器输出终止时刻的输出z
t
,最后通过全连接层转变输出格式;
51.步骤3,构建高保真音频重构损失。
52.利用输入与重构音频样本,按照公式计算均方误差,其中,t=1,2,3
…
l,l=160为音频长度,x
t
表示原始数据,表示重构数据。
53.利用输入音频样本,按照公式计算每一个时刻音频数据的重构误差
权重,其中,λ=2。其中,x
t2
表示语音信号强度,权值w随着x
t2
的增大而减小,λ>0为尺度参数,λ越大,权值w随x
t2
的增大而减小得越快;
54.将均方误差与重构误差权重对应相乘,即按照公式计算得到高保真音频重构损失。其中,λ为尺度参数,音频能量越高的区域权重越小,公式表达的高保真音频重构损失函数是一种自适应加权均方误差损失函数,允许在语音信号强度大的地方产生较大的重构误差,在语音信号强度小的地方限制误差;由于对抗样本的微弱扰动往往添加在信号强度较大的区域的原因,该方法既保证了语音在重构后强度大的区域允许有误差,又保证了语音在重构后信号强度小的区域无损失
55.步骤4,设置训练参数并训练网络。
56.设置训练参数,包括迭代轮次t=30、小批量尺寸s=64以及学习率η=1
×
10-4
,并选择优化算法,其中,优化算法是指基于1阶梯度的优化算法,包括sgd(stochastic gradient descent,随机梯度下降),momentum-sgd(stochastic gradient descent with momentum,带动量的随机梯度下降),rmsprop(root mean square prop,均方根传递),adam(adaptive moment estimation,自适应矩估计)等,本实施例中,优化算法采用adam算法,adam优化器参数为β1=0.99,β2=0.999。
57.读取对抗样本修复训练数据集,将原始音频数据集中的八类英文音频数据,每类音频数据划分为7个小批量数据集,得到预处理后对抗样本修复训练数据集。
58.利用预处理后对抗样本修复训练数据集,针对八类英文音频数据集,将7个小批量数据依次输入到rae网络中,利用adam算法,按照前向传播、反向传播、权重更新的顺序,重复30轮,共计迭代210次后停止训练,得到训练好的rae网络。
59.步骤5,利用训练好的rae模型修复对抗样本。
60.读取对抗样本,利用训练好的rae网络模型修复对抗样本,输出修复后的样本。,其中,所述对抗样本是指通过语音对抗样本生成算法所生成的一种音频数据,其通过在干净样本上添加微弱扰动而诱导语音识别模型产生错误识别结果;对抗样本的音频数据格式为“.wav”,采样频率为16khz,时长小于等于1秒,即读取的音频数据序列长度小于等于16000,对音频数据时长小于1秒的序列,在末尾进行补零操作,使其长度达到16000。
61.将对抗样本与修复后的样本输入语音识别模型,观察对抗样本修复效果,具体包括两方面内容,一方面观察对抗样本与修复后的样本的声谱差异,另一方面观察对抗样本与修复后的样本输入到语音识别模型识别后的结果,若修复后的样本识别结果正确,则修复成功,否则,修复失败。
62.下面,结合实验结果对本发明的效果做进一步的描述。
63.1.本发明的实验条件:
64.本实施例所使用的软件平台为:windows10操作系统和spyder。
65.本实施例所使用的硬件设备为intel core(tm)i7-9700k@3.60ghz
×
8,gpu nvidia geforce gtx 1080ti,11gb显存。
66.本实施例所使用python版本为python 3.7.3,所使用的库及对应版本分别
pytorch 1.1.0,torchaudio 0.8.0,numpy 1.21.0。
67.2.本发明的实验结果分析:
68.本发明的实验是利用本发明构建的一种具有听觉高保真度特点的语音对抗样本修复方法修复对抗样本,输出修复后的样本,观察对抗样本与修复后的样本的声谱差异,并通过语音识别模型对对抗样本与修复后的样本进行对比,得到识别结果。
69.对抗样本与修复后的样本的声谱差异,图3是on类数据的原始音频声谱图,图4是on类数据的对抗样本声谱图,图5是由本发明方法生成的on类音频修复后的样本声谱图,图3与图5声谱图相似度高,图4与图5存在一定差异。
70.根据公式计算语音对抗样本修复成功率,其中,z=1,2...k,k=8为语音音频类别,nz=500为一类对抗样本数据的总个数,mz为修复成功的该类对抗样本个数,分别统计不同语音类别的对抗样本修复成功率。结果如表1所示。
71.表1不同音频类别下的对抗样本修复成功率结果
[0072][0073]
对照表1的结果,从对不同音频类别的修复成功率来看,本发明提出的一种具有听觉高保真特点的语音对抗样本修复方法在对down、go、left、off、on、right、stop、up这八种不同类别的英文音频的不同对抗样本修复中,除对stop类的四种对抗样本修复成功率低于50%外,对其余七类音频的pgd攻击以及deepfool攻击样本的修复成功率均超过80%,其中,对go类的deepfool攻击样本的修复成功率以及对on类音频的pgd攻击以及deepfool攻击样本的修复成功率分别达90.2%、93.6%、95%;从对不同攻击类型的修复成功率来看,本发明提出的一种具有听觉高保真特点的语音对抗样本修复方法在对pgd攻击、deepfool攻击、sa攻击、ga攻击这种对抗样本的修复中,除off类音频外,对pgd攻击、deepfool攻击以及ga攻击的对抗样本修复成功率比对sa攻击的对抗样本修复成功率高。
[0074]
本发明生成的修复样本可在自动语音指令识别系统上的识别结果为给定的任意指令,与其他语音对抗样本修复算法相比,在对抗样本识别结果和原始标签错误率相同的情况下,本方法修复成功率更高,从听觉上也具备保真性,能够适用于更低信噪比情况下的对抗样本。
[0075]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。