1.本发明涉及模式识别领域,尤其涉及一种基于语音增强的说话人识别方法及系统。
背景技术:
2.声纹识别,是一项提取说话人声音特征和说话内容信息,自动核验说话人身份的技术。随着人工智能在人们日常生活中的广泛应用,声纹识别技术也逐渐突显出了它的作用,比如对个人智能设备(如手机、车辆和笔记本电脑)的基于语音的认证;保证银行交易和远程支付的交易安全;以及自动身份标记。
3.但是由于现实生活背景噪声的复杂,用于识别的声音总是包含着各种各样的噪声,这将会导致声纹识别效果不佳,因此如何克服待识别声音的噪声问题是声纹识别技术应用到现实生活中亟待解决的问题。
技术实现要素:
4.本发明提出一种基于语音增强的说话人识别方法及系统,用于解决或者至少部分解决现有技术中声纹识别效果不佳的技术问题。
5.为了解决上述技术问题,本发明第一方面提供了一种基于语音增强的说话人识别方法,包括:
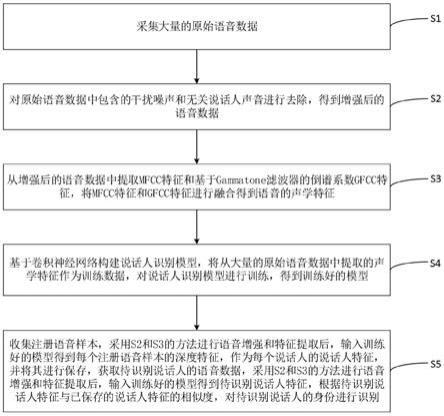
6.s1:采集大量的原始语音数据;
7.s2:对原始语音数据中包含的干扰噪声和无关说话人声音进行去除,得到增强后的语音数据;
8.s3:从增强后的语音数据中提取mfcc特征和基于gammatone滤波器的倒谱系数gfcc特征,将mfcc特征和gfcc特征进行融合得到语音的声学特征;
9.s4:基于卷积神经网络构建说话人识别模型,将从大量的原始语音数据中提取的声学特征作为训练数据,对说话人识别模型进行训练,得到训练好的模型;
10.s5:收集注册语音样本,采用s2和s3的方法进行语音增强和特征提取后,输入训练好的模型得到每个注册语音样本的深度特征,作为每个说话人的说话人特征,并将其进行保存;获取待识别说话人的语音数据,采用s2和s3的方法进行语音增强和特征提取后,输入训练好的模型得到待识别说话人特征,根据待识别说话人特征与已保存的说话人特征的相似度,对待识别说话人的身份进行识别。
11.在一种实施方式中,步骤s1采用录音的方式进行原始语音数据的采集。
12.在一种实施方式中,步骤s2采用生成对抗网络对原始语音数据中包含的干扰噪声和无关说话人声音进行去除,实现端到端的语音增强。
13.在一种实施方式中,步骤s3包括:
14.s3.1:对增强后的语音数据进行语音活动端点检测,消除长时间的静音段;
15.s3.2:对步骤s3.1得到的语音进行预处理;
16.s3.3:对预处理后的语音进行快速傅里叶变换得到各帧的频谱,并对语音信号的频谱取模平方得到语音信号的功率谱;
17.s3.4:将快速傅里叶变换得到的功率谱通过一组梅尔尺度的三角滤波器,得到每一帧数据在三角滤波器对应频段的能量值;
18.s3.5:对每一帧数据在三角滤波器对应频段的能量值取对数,计算算每个滤波器组输出的对数能量;
19.s3.6:将对数能量代入离散余弦变换,求出l阶的梅尔倒谱系数;
20.s3.7:将快速傅里叶变换得到的功率谱,通过gammatone滤波器,再进行指数压缩和离散余弦变换得到语音信号的gfcc特征;
21.s3.8:将语音信号的mfcc特征和gfcc特征进行级联,得到语音信号的声学特征。
22.在一种实施方式中,步骤s4包括:
23.将收集的大量的原始语音数据通过语音增强,然后从中提取声学特征作为训练数据,输入到说话人识别模型进行训练,得到训练好的模型;
24.在一种实施方式中,步骤s5中注册数据包括每个说话人的h个语音样本,根据待识别说话人特征与已注册的说话人特征的相似度,对待识别说话人的身份进行识别,包括:
25.将注册数据中的每个语音样本进行语音增强和特征提取后,将得到的声学特征通过说话人识别模型的卷积神经网络提取每个语音样本的深度特征;
26.将每个说话人的h个深度特征取平均,作为每个说话人的说话人特征,保存在数据库中;
27.将待识别说话人的语音数据通过语音增强和特征提取后,输入训练好的模型得到待识别说话人特征;
28.计算待识别说话人特征和数据库中保存的所有说话人特征的余弦相似度 cos,如果最大的余弦相似度大于设定阈值,则该余弦相似度对应的数据库中的说话人即为识别到的说话人身份,否则拒绝。
29.基于同样的发明构思,本发明第二方面提供了一种基于语音增强的说话人识别系统,包括:
30.语音采集模块,用于采集大量的原始语音数据;
31.语音增强模块,用于对原始语音数据中包含的干扰噪声和无关说话人声音进行去除,得到增强后的语音数据;
32.语音特征提取模块,用于从增强后的语音数据中提取mfcc特征和基于 gammatone滤波器的倒谱系数gfcc特征,将mfcc特征和gfcc特征进行融合得到语音的声学特征;
33.模型训练模块,用于基于卷积神经网络构建说话人识别模型,将从大量的原始语音数据中提取的声学特征作为训练数据,对说话人识别模型进行训练,得到训练好的模型;
34.说话人识别模块,收集注册语音样本,采用语音增强模块和语音特征提取模块的方法进行语音增强和特征提取后,输入训练好的模型得到每个注册语音样本的深度特征,作为每个说话人的说话人特征,并将每个说话人的说话人特征进行保存;获取待识别说话人的语音数据,采用语音增强模块和语音特征提取模块的方法进行语音增强和特征提取后,输入训练好的模型得到待识别说话人特征,根据待识别说话人特征与已保存的说话人特征的相似度,对待识别说话人的身份进行识别。
35.本技术实施例中的上述一个或多个技术方案,至少具有如下一种或多种技术效果:
36.本发明提供的一种基于语音增强的说话人识别方法,使用端到端的语音增强方法,去除语音中的噪声和无关说话人声音,而且在声纹识别过程中使用了更加具有噪声鲁棒性的gfcc特征,并将mfcc特征和gfcc特征进行融合得到语音的声学特征,可以提高噪声鲁棒性,再基于卷积神经网络构建说话人识别模型,利用训练数据对模型进行训练,收集注册语音样本,提取每个注册说话人的说话人特征,并将其进行保存,根据待识别说话人特征与已保存的说话人特征的相似度,对待识别说话人的身份进行识别。解决了现有技术中由于语音中包含的噪声而导致声纹识别效果不佳的问题,提高声纹识别的识别准确率。
附图说明
37.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
38.图1为本发明实施提供的一种基于语音增强的说话人识别方法的流程图;
39.图2为本发明实施中语音特征mfcc提取流程图;
40.图3为本发明实施中语音特征gfcc的提取流程图;
41.图4为本发明实施提供的一种基于语音增强的说话人识别系统的框图。
具体实施方式
42.本发明的目的在于,提供一种基于语音增强的说话人识别方法,解决了现有技术中待识别语音中包含噪声,无法进行准确特征提取而导致的识别效果不佳的问题。
43.本发明的主要构思如下:
44.首先采集大量的原始语音数据,然后对原始语音数据中包含的干扰噪声和无关说话人声音进行去除,得到增强后的语音数据;接着从增强后的语音数据中提取mfcc特征和基于gammatone滤波器的倒谱系数gfcc特征,将mfcc特征和gfcc特征进行融合得到语音的声学特征;然后基于卷积神经网络构建说话人识别模型,将从大量的原始语音数据中提取的声学特征作为训练数据,对说话人识别模型进行训练,得到训练好的模型;收集注册语音样本,采用s2和s3 的方法进行语音增强和特征提取后,输入训练好的模型得到每个注册语音样本的深度特征,作为每个说话人的说话人特征,并将其进行保存;再获取待识别说话人的语音数据,采用s2和s3的方法进行语音增强和特征提取后,输入训练好的模型得到待识别说话人特征,根据待识别说话人特征与已保存的说话人特征的相似度,对待识别说话人的身份进行识别。
45.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
46.实施例一
47.本发明实施例提供了一种基于语音增强的说话人识别方法,包括:
48.s1:采集大量的原始语音数据;
49.s2:对原始语音数据中包含的干扰噪声和无关说话人声音进行去除,得到增强后的语音数据;
50.s3:从增强后的语音数据中提取mfcc特征和基于gammatone滤波器的倒谱系数gfcc特征,将mfcc特征和gfcc特征进行融合得到语音的声学特征;
51.s4:基于卷积神经网络构建说话人识别模型,将从大量的原始语音数据中提取的声学特征作为训练数据,对说话人识别模型进行训练,得到训练好的模型;
52.s5:收集注册语音样本,采用s2和s3的方法进行语音增强和特征提取后,输入训练好的模型得到每个注册语音样本的深度特征,作为每个说话人的说话人特征,并将每个说话人的说话人特征进行保存;获取待识别说话人的语音数据,采用s2和s3的方法进行语音增强和特征提取后,输入训练好的模型得到待识别说话人特征,根据待识别说话人特征与已保存的说话人特征的相似度,对待识别说话人的身份进行识别。
53.具体来说,说话人识别模型训练模块中,网络模型使用卷积神经网络,分类器使用softmax,训练好的模型为离线模型。注册语音数据中包括多个说话人,每个说话人包括h个语音样本。
54.请参见图1,为本发明实施提供的一种基于语音增强的说话人识别方法的流程图。
55.在一种实施方式中,步骤s1采用录音的方式进行原始语音数据的采集。
56.在一种实施方式中,步骤s2采用生成对抗网络对原始语音数据中包含的干扰噪声和无关说话人声音进行去除,实现端到端的语音增强。
57.生成对抗网络是一个编码器
‑
解码器的完全卷积结构,用以去除语音中的噪声生成干净的语音波形;对抗网络在纯净语音波形和噪声语音波形基础上设定一个阈值,用于判断生成的语音波形是否纯净,当生成的语音波形和噪声语音波形的值达到该阈值时,则说明生成的语音波形已足够纯净。
58.本发明在生成对抗框架内实现一种端到端语音增强方法去除语音中的干扰噪声和无关说话人声音。
59.具体实施过程中,将纯净语音和生活中常见噪声以随机信噪比进行混合,得到与纯净语音相对应的噪声语音,然后使用纯净语音数据集和对应的噪声语音数据集训练得到一个实现端到端语音增强的生成对抗网络。
60.下面以训练一个包含1000个纯净语音的数据集的模型为例具体说明语音模型训练过程。
61.将纯净语音集和生活噪声数据集以随机信噪比(一般在
‑
10db至10db之间) 进行混合,得到与纯净语音集相对应的噪声语音集。将噪声语音通过生成网络得到生成的纯净语音,然后将生成的纯净语音和真实的纯净语音通过判别网络判断生成的纯净语音是否是真实的纯净语音:如果得到的是生成的纯净语音,辨别器应该输出0,如果是真实的纯净语音应该输出1。然后通过损失函数得到误差梯度反向传播来更新参数,直到判别器无法准确判断生成的纯净语音和真实的纯净语音时,生成网络即为已经训练好的语音增强网络。直观上来说就是:判别器不得不告诉生成器如何调整从而使它生成的纯净语音变得更加真实。
62.在一种实施方式中,步骤s3包括:
63.s3.1:对增强后的语音数据进行语音活动端点检测和消除长时间的静音段;
64.s3.2:对步骤s3.1得到的语音进行预处理;
65.s3.3:对预处理后的语音进行快速傅里叶变换得到各帧的频谱,并对语音信号的频谱取模平方得到语音信号的功率谱;
66.s3.4:将快速傅里叶变换得到的功率谱通过一组梅尔尺度的三角滤波器,得到每一帧数据在三角滤波器对应频段的能量值;
67.s3.5:对每一帧数据在三角滤波器对应频段的能量值取对数,计算算每个滤波器组输出的对数能量;
68.s3.6:将对数能量代入离散余弦变换,求出l阶的梅尔倒谱系数;
69.s3.7:将快速傅里叶变换得到的功率谱,通过gammatone滤波器,再进行指数压缩和离散余弦变换得到语音信号的gfcc特征;
70.s3.8:将语音信号的mfcc特征和gfcc特征进行级联,得到语音信号的声学特征。
71.具体实施过程中,预处理包括预加重、分帧和加窗。特征提取的具体步骤如下:
72.s301:对增强后的语音音进行语音活动端点检测(vad),消除长时间的静音期;
73.s302:将语音信号通过一个高通滤波器进行预加重:h(z)=1
‑
μz
‑1,h(z) 为高通滤波器;μ预加重系数,通常取0.97;z为语音信号。
74.s303:语音信号的采样频率为16khz,先将512个采样点集合成一帧,对应的时间长度是512/16000
×
1000=32ms。让两相邻帧之间有一段重叠区域,此重叠区域包含256个取样点,为采样点512的1/2。
75.s304:假设分帧后的信号为s(n),n=0,1,...,n
‑
1,n为总帧数,将每一帧乘以汉明窗:
76.x(n)=s(n)
×
w(n), w(n)为汉明窗;n为总帧数;n=0,1,...,n
‑
1。
77.s305:对分帧加窗后的各帧信号x(n)进行快速傅里叶变换得到各帧的频谱,并对语音信号的频谱取模平方得到语音信号的功率谱。语音信号的离散傅里叶变换(语音信号以离散的形式存储)为:
[0078][0079]
x(n)为输入的语音信号,t表示傅里叶变换的点数。
[0080]
s306:将快速傅里叶变换得到的功率谱|x(k)|2通过一组梅尔尺度的三角滤波器h
m
(k),0≤m≤m,m为滤波器的个数:将功率谱分别跟每一个滤波器进行频率相乘累加,得到的值即为该帧数据在在该滤波器对应频段的能量值
[0081]
s307:对能量值取log,计算每个滤波器组输出的对数能量为:
[0082][0083]
t表示傅里叶变换的点数;m为滤波器的个数;|x(k)|2为s4得到的功率谱;h
m
(k),0≤m≤m为一组梅尔尺度的三角滤波器。
[0084]
s308:将s307的对数能量代入离散余弦变换,求出l阶的梅尔倒谱系数 mfcc:
[0085][0086]
l指mfcc系数阶数,通常取12
‑
16;m是三角滤波器个数,0≤m≤m。
[0087]
s309:将快速傅里叶变换得到的功率谱,通过gammatone滤波器,再进行指数压缩和离散余弦变换dct得到语音信号的gfcc特征。
[0088]
s310:将语音信号的mfcc特征和gfcc特征进行级联,得到语音信号的 gmcc特征。
[0089]
其中,图2和图3分别为本发明实施中语音特征mfcc提取流程图和语音特征gfcc的提取流程图。
[0090]
在一种实施方式中,步骤s4包括:
[0091]
将收集的大量的原始语音数据通过语音增强,然后从中提取声学特征作为训练数据,输入到说话人识别模型进行训练,得到训练好的模型。
[0092]
具体来说,训练模型为离线过程,说话人识别模型的训练:
[0093]
采用录音的方式收集训练样本;将收集到的语音样本通过语音预处理模块(语音增强模块和语音特征提取模块)得到语音的gmcc特征;将gmcc特征作为模型的输入,采用卷积神经网络结构和softmax分类训练说话人识别模型。
[0094]
下面以训练一个包含1000个说话人的模型为例具体说明说话人识别模型训练过程。
[0095]
采集每个说话人的样本,每人采集100个样本;将所有的语音样本通过语音预处理模块(语音增强模块和语音特征提取模块)得到语音的gmcc特征作为卷积神经网络(说话人识别模型)的训练数据,其中,将所有训练数据随机分为 5:1,分别作为训练集和验证集;使用训练集训练卷积网络,当训练过的卷积网络在验证集上的识别精度基本保持不变时,卷积网络训练完成;否则继续训练。该训练完成的卷积网络即为说话人识别离线模型。
[0096]
在一种实施方式中,步骤s5中注册数据包括每个说话人的h个语音样本,根据待识别说话人特征与已注册的说话人特征的相似度,对待识别说话人的身份进行识别,包括:
[0097]
将注册数据中的每个语音样本进行语音增强和特征提取后,将得到的声学特征通过说话人识别模型的卷积神经网络提取每个语音样本的深度特征;
[0098]
将每个说话人的h个深度特征取平均,作为每个说话人的说话人特征,保存在数据库中;
[0099]
将待识别说话人的语音数据通过语音增强和特征提取后,输入训练好的模型得到待识别说话人特征;
[0100]
计算待识别说话人特征和数据库中保存的所有说话人特征的余弦相似度 cos,如果最大的余弦相似度大于设定阈值,则该余弦相似度对应的数据库中的说话人即为识别到的说话人身份,否则拒绝。
[0101]
注册模式:
[0102]
采用录音的方式收集注册样本;将收集到的注册样本通过语音预处理模块得到语音的gmcc特征;将语音的gmcc特征通过说话人识别离线模型提取每个语音样本的deep feature(深度特征);生成注册数据(即每个说话人的说话人特征),存放在数据库中。
[0103]
例如,采集10个说话人的样本(每人20个语音样本);语音预处理模块处理所有语
音样本,得到语音的gmcc特征;将语音的gmcc特征通过说话人识别离线模型得到200个语音样本的deep feature;然后将每个说话人的20个deepfeature取平均,作为每个说话人特征;将10个说话人特征保存在数据库中: speaker0,speaker1,......,speaker9。
[0104]
识别模式:
[0105]
采用录音的方式收集待识别样本;将待识别样本通过语音预处理模块得到 gmcc特征;将gmcc特征通过说话人识别离线模型得到待识别样本的deepfeature,作为待识别说话人特征;计算待识别说话人特征和数据库中的所有说话人特征的余弦相似度cos,如果最大的余弦相似度大于某个阈值,则该余弦相似度对应的数据库中的说话人即为识别到的说话人;否则拒绝。
[0106]
举例来说,采集此说话人的语音数据一条;通过语音预处理模块得到gmcc 特征;将gmcc特征通过说话人识别离线模型得到该语音数据的deep feature,作为此说话人特征;将此说话人特征和数据库中保存的10个说话人特征计算余弦相似度得到cos0,cos1,...,cos9,找到这10个余弦相似度中的最大值cos_max和对应说话人的编号speaker_x,如果这个最大值大于设定阈值,则接受此说话人为speaker_x,否则识别为未注册说话人。
[0107]
综上所述,本发明通过语音采集、语音增强、语音特征提取、说话人模型训练、说话人注册、说话人识别实现了一种基于语音增强的说话人识别方法。
[0108]
相对于现有技术,本发明的有益效果是:
[0109]
本发明提出的一种基于语音增强的说话人识别方法及系统,使用端到端的语音增强方法,去除语音中的噪声和无关说话人声音,而且在声纹识别过程中使用了更加具有噪声鲁棒性的gfcc特征,提高了整个系统的噪声鲁棒性,可以解决由于语音中包含的噪声而导致声纹识别效果不佳的问题,提高声纹识别系统的识别准确率。
[0110]
实施例二
[0111]
基于同样的发明构思,本实施例提供了一种基于语音增强的说话人识别系统,请参见图4,该系统包括:
[0112]
语音采集模块201,用于采集大量的原始语音数据;
[0113]
语音增强模块202,用于对原始语音数据中包含的干扰噪声和无关说话人声音进行去除,得到增强后的语音数据;
[0114]
语音特征提取模块203,用于从增强后的语音数据中提取mfcc特征和基于 gammatone滤波器的倒谱系数gfcc特征,将mfcc特征和gfcc特征进行融合得到语音的声学特征;
[0115]
模型训练模块204,用于基于卷积神经网络构建说话人识别模型,将从大量的原始语音数据中提取的声学特征作为训练数据,对说话人识别模型进行训练,得到训练好的模型;
[0116]
说话人识别模块205,用于注册说话人和识别说话人,收集注册语音样本,采用语音增强模块和语音特征提取模块的方法进行语音增强和特征提取后,输入训练好的模型得到每个注册语音样本的深度特征,作为每个说话人的说话人特征,并将其进行保存;获取待识别说话人的语音数据,采用语音增强模块和语音特征提取模块的方法进行语音增强和特征提取后,输入训练好的模型得到待识别说话人特征,根据待识别说话人特征与已保存的
说话人特征的相似度,对待识别说话人的身份进行识别。
[0117]
由于本发明实施例二所介绍的系统,为实施本发明实施例一种基于语音增强的说话人识别方法所采用的系统,故而基于本发明实施例一所介绍的方法,本领域所属技术人员能够了解该系统的具体结构及变形,故而在此不再赘述。凡是本发明实施例一的方法所采用的系统都属于本发明所欲保护的范围。
[0118]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。