1.本发明涉及一种基于多模态融合的抑郁状态识别方法。
背景技术:
2.抑郁症是一种在世界范围内典型且常见的精神性疾病,覆盖各个年龄阶段,给患者造成严重的健康问题。现行的抑郁症临床诊断方法依赖医生的临床经验和患者填写的相关量表,整个过程耗时较长,诊断流程效率低下,受限于国内现阶段的医疗资源,患者的筛查效率更加低效。并且大部分早期患者对抑郁症类精神疾病不够重视,到医院求助的意愿相对身体疾病比较消极。
3.近年来,基于生理、行为等多种指标进行抑郁评估的研究均取得一定成果,但目前尚未有明确的生物标记物可用于识别抑郁症,研究人员仍在不断寻找一种客观有效的抑郁评估方法。
技术实现要素:
4.为解决上述问题,提供一种基于多模态融合的抑郁状态识别方法,本发明采用了如下技术方案:
5.本发明提供了一种基于多模态融合的抑郁状态识别方法,包括以下步骤:步骤s1,采集被试者的语音数据和人脸数据;步骤s2,对语音数据进行语音预处理,得到预处理的语音数据;步骤s3,将预处理的语音数据通过阿里云接口转为语音文本,并对语音文本进行文本预处理,得到预处理的语音文本;步骤s4,对人脸数据进行视频预处理,得到视频数据;步骤s5,将预处理的语音数据映射到时频域上,得到二维矩阵;步骤s6,构建多模态融合神经网络模型,将二维矩阵、预处理的语音文本和视频数据共同输入到多模态融合神经网络模型,以被试者是否抑郁作为训练标签进行训练,得到完成训练的多模态融合神经网络模型;步骤s7,将待测语音数据输入到完成训练的多模态融合神经网络模型得到对应的多个分类结果,再以投票法的方式选择类别更多的训练标签作为语音信号的最终分类结果;其中,多模态融合神经网络模型包括视频处理模块、语音文本处理模块、时频域映射模块、全连接层和softmax层,视频处理模块包括卷积层、池化层和全连接层,语音文本处理模块包括卷积层、双向lstm层、注意力层和全连接层;时频域映射模块包括卷积层、双向lstm层、注意力层和全连接层。
6.本发明提供的一种基于多模态融合的抑郁状态识别方法,还可以具有这样的技术特征,其中,双向lstm层由作为前向lstm层的多个lstm单元以及作为后向lstm层的多个lstm单元构成,前向lstm层的多个lstm单元用于接收原始顺序的输入信号,后向lstm层的多个lstm单元用于接收反向顺序的输入信号。
7.本发明提供的一种基于多模态融合的抑郁状态识别方法,还可以具有这样的技术特征,其中,lstm单元由输入门i
t
、遗忘门f
t
、输出门o
t
三个门函数和细胞状态组成;lstm单元的运行过程包括以下步骤:第一步,通过遗忘门决定丢弃的信息,并计算输入门i
t
、遗忘
门f
t
、输出门o
t
的值,计算公式为:i
t
=δ(w
i
x
t
+u
i
h
t
‑1+b
i
),f
t
=δ(w
f
x
t
+u
f
h
t
‑1+b
f
),o
t
=δ(w0x
t
+u0h
t
‑1+b0),式中,x
t
为当前数据输入,h
t
为当前隐藏层的输入,h
t
‑1为上一状态隐藏层的输出,w
i
、w
f
、w0为对应的权重系数矩阵,b
i
、b
f
、b0为对应的偏置项,δ为sigmoid函数;第二步,计算细胞状态候选值计算公式为:式中,w
c
、u
c
为对应的权重系数矩阵,b
c
为偏置项,tanh为激活函数;第三步,根据上一细胞状态值c
t
‑1和细胞状态候选值计算当前细胞状态值c
t
,计算公式为:第四步,计算lstm单元的当前状态输出h
t
,计算公式为:h
t
=o
t tanh(c
t
)。
8.本发明提供的一种基于多模态融合的抑郁状态识别方法,还可以具有这样的技术特征,其中,注意力层的输出根据以下公式来得到:u
t
=tanh(w
ω
h
t
+b
ω
),式中,u
t
为h
t
通过多层感知机映射得到的隐式表达,u
ω
为整个语音段矢量,α
t
为权重系数,w
ω
为权重系数矩阵,b
ω
为偏置项,s为语音矢量。
9.本发明提供的一种基于多模态融合的抑郁状态识别方法,还可以具有这样的技术特征,其中,语音预处理是包括人工筛查排除明显的噪音片段、高通滤波、降采样以及静音片段检测和移除。
10.本发明提供的一种基于多模态融合的抑郁状态识别方法,还可以具有这样的技术特征,其中,语音数据片段时长为30秒。
11.本发明提供的一种基于多模态融合的抑郁状态识别方法,还可以具有这样的技术特征,其中,文本预处理是先人工筛查明显的错字、漏字,并将语音文本与语音数据逐一对应,再将语音文本嵌入到向量领域。
12.本发明提供的一种基于多模态融合的抑郁状态识别方法,还可以具有这样的技术特征,其中,步骤s5中,通过短时傅里叶变换来将预处理的语音数据映射到时频域上。
13.发明作用与效果
14.根据本发明的一种基于多模态融合的抑郁状态识别方法,设计了一种多模态融合神经网络模型,并将语音文本、视频数据以及语音数据映射到时频域上的二维矩阵共同输入使用该神经网络模型,从语言、面部表情等多方面对受试者更加客观有效进行抑郁状态识别评估,与现有的基于单一模态的机器学习模型相比,融合多模态数据源的神经网络模型的性能进一步提高。
15.同时,本发明中的多模态神经网络模型中还融合了注意力机制,能通过自学习的方式调整其权重系数,重点观察语音中的部分片段,因此能很好地解决因语音信号特征分布的稀疏性对分类结果造成的干扰等技术问题,因此进一步提高抑郁筛查的准确性和稳定性。
附图说明
16.图1是本发明实施例中的基于多模态的融合attention与bi
‑
lstm的卷积神经网络结构示意图;
17.图2是本发明实施例中注意力机制结构示意图;
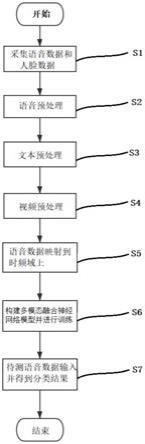
18.图3是本发明实施例中一种基于多模态融合的抑郁状态识别方法流程图。
具体实施方式
19.为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结合实施例及附图对本发明的一种基于多模态融合的抑郁状态识别方法作具体阐述。
20.<实施例>
21.图1是本发明实施例中的基于多模态的融合attention与bi
‑
lstm的卷积神经网络结构示意图。
22.如图1所示,本发明实施例中的基于多模态的融合attention与bi
‑
lstm的卷积神经网络结构包括视频处理模块、语音文本处理模块、时频域映射模块、全连接层和softmax层。其中视频处理模块包括卷积层、池化层和全连接层。语音文本处理模块包括卷积层、双向lstm层、注意力层和全连接层。时频域映射模块包括卷积层、双向lstm层、注意力层和全连接层。
23.双向lstm层由作为前向lstm层的多个lstm单元以及作为后向lstm层的多个lstm单元构成。前向lstm层的多个lstm单元用于接收原始顺序的输入信号。后向lstm层的多个lstm单元用于接收反向顺序的输入信号。
24.其中,lstm单元由输入门i
t
、遗忘门f
t
、输出门o
t
三个门函数和细胞状态组成。
25.lstm单元的运行过程包括以下步骤:
26.第一步,通过遗忘门决定丢弃的信息,并计算输入门i
t
、遗忘门f
t
、输出门o
t
的值,计算公式为:
27.i
t
=δ(w
i
x
t
+u
i
h
t
‑1+b
i
)
28.f
t
=δ(w
f
x
t
+u
f
h
t
‑1+b
f
)
29.o
t
=δ(w0x
t
+u0h
t
‑1+b0)
30.式中,x
t
为当前数据输入,h
t
为当前隐藏层的输入,h
t
‑1为上一状态隐藏层的输出,w
i
、w
f
、w0为对应的权重系数矩阵,b
i
、b
f
、b0为对应的偏置项,δ为sigmoid函数;
31.第二步,计算细胞状态候选值计算公式为:
[0032][0033]
式中,w
c
、u
c
为对应的权重系数矩阵,b
c
为偏置项,tanh为激活函数;
[0034]
第三步,根据上一细胞状态值c
t
‑1和细胞状态候选值计算当前细胞状态值c
t
,计算公式为:
[0035][0036]
第四步,计算lstm单元的当前状态输出h
t
,计算公式为:
[0037]
h
t
=o
t tanh(c
t
)。
[0038]
图2是本发明实施例中注意力机制结构示意图。
[0039]
如图2所示,注意力机制是一系列权重参数,对于一段语音并不是从头到尾每个部分都给予同样的关注度,而是通过自学习的方式调整权重系数,重点观察语音的部分片段。
[0040]
本实施例中,通过多层感知机将双向lstm的输出h
t
映射为隐式表达u
t
,然后用u
t
与整个语音段矢量u
ω
的相似性来衡量各个片段的重要性,再通过一个softmax函数得到标准化后的权重系数α
t
,最后语音矢量s经过h
t
加权求和得到注意力层的输出。具体计算公式为:
[0041]
u
t
=tanh(w
ω
h
t
+b
ω
)
[0042][0043][0044]
式中,u
t
为h
t
通过多层感知机映射得到的隐式表达,u
ω
为整个语音段矢量,α
t
为权重系数,w
ω
为权重系数矩阵,b
ω
为偏置项,s为语音矢量。
[0045]
图3为本发明实施例中一种基于多模态融合的抑郁状态识别方法流程图。
[0046]
如图3所示,一种基于多模态融合的抑郁状态识别方法包括以下步骤:
[0047]
步骤s1,采集被试者的语音数据和人脸数据。
[0048]
步骤s2,对语音数据进行语音预处理,得到预处理的语音数据。本实施例中采用截止频率为137.8hz的二阶巴特沃斯滤波器进行高通滤波,降低低频噪音对人声有效信息的干扰。用工具包librosa将语音信号统一采样到16000hz。采用工具包pyaudioanalysis进行有声片段和静音片段的检测并去除非语音的无声片段。
[0049]
步骤s3,将预处理的语音数据通过阿里云接口转为语音文本,并对语音文本进行文本预处理,得到预处理的语音文本。
[0050]
步骤s4,对人脸数据进行视频预处理,得到视频数据。
[0051]
步骤s5,将预处理的语音数据映射到时频域上,得到二维矩阵。本实施例中通过短时傅里叶变换来将预处理的语音数据映射到时频域上。其中,短时傅里叶变换选用hamming窗,nfft=1024,窗长0.1s,滑动步长0.05s。
[0052]
步骤s6,构建多模态融合神经网络模型,将二维矩阵、预处理的语音文本和视频数据共同输入到多模态融合神经网络模型,以被试者是否抑郁作为训练标签进行训练,得到完成训练的多模态融合神经网络模型。
[0053]
本实施例中批处理大小(batch size)为512,交叉熵(cross entropy)为损失函数,优化器为adam,训练次数为500次,初始学习率为0.0001,学习率会随着迭代步数的增加而衰减,每经过100次训练学习率
×
0.5。
[0054]
步骤s7,将待测语音数据输入到完成训练的多模态融合神经网络模型得到对应的多个分类结果,再以投票法的方式选择类别更多的训练标签作为语音信号的最终分类结果。
[0055]
本发明实施例还提供了以下三种语音抑郁状态分类结果的评价指标,accuracy、f1分数以及auc值。这三种评价指标的具体定义如下:
[0056][0057][0058]
f1分数是召回率和精确率的调和平均值,取值范围[0,1]。
[0059]
auc值为受试者工作特征曲线(receiver operating characteristic curve,
roc)与坐标轴围成的面积,roc曲线的横坐标是纵坐标是曲线处于y=x上方,取值范围[0.5,1]。
[0060]
其中,tp,fp,fn,tn的定义如表1所示。
[0061]
表1语音抑郁状态分类结果混淆矩阵
[0062] 抑郁被试的音频正常被试的音频判断属于抑郁被试的音频true positive(tp)false positive(fp)判断属于正常被试的音频false negative(fn)true negative(tn)
[0063]
上述三种评价指标的值都与分类性能正相关,值越大代表分类的结果越好。
[0064]
如上,通过一种基于多模态融合的抑郁状态识别方法,将采集到的语音经处理后送入本发明设计的多模态融合神经网络模型进行训练,得到分类结果,并得到该分类结果的评价。
[0065]
实施例作用与效果
[0066]
根据本实施例提供的一种基于多模态融合的抑郁状态识别方法,设计了一种多模态融合神经网络模型,并将语音文本、视频数据以及语音数据映射到时频域上的二维矩阵共同输入使用该神经网络模型,从语言、面部表情等多方面对受试者更加客观有效进行抑郁状态识别评估,与现有的基于单一模态的机器学习模型相比,融合多模态数据源的神经网络模型的性能进一步提高。
[0067]
同时,本实施例中的多模态神经网络模型中还融合了注意力机制,能通过自学习的方式调整其权重系数,重点观察语音中的部分片段,因此能很好地解决因语音信号特征分布的稀疏性对分类结果造成的干扰等技术问题,因此进一步提高抑郁筛查的准确性和稳定性。
[0068]
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。