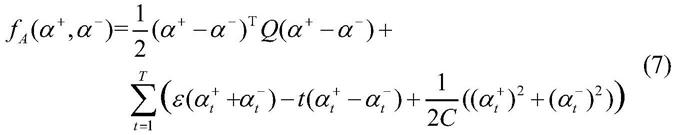
1.本发明涉及音频特征表示方法,属于语种分类领域。
背景技术:
2.近年来,随着智能技术的发展与全球化进程的不断推进,人们在各个地区的来往和贸易越来越密切,人们对于跨越语言的交流需求也日益增长。作为语音前端处理过程中的重要环节与为未来人机交互的重要接口,语种识别的准确率和效率,对于智能系统的发展具有重大的影响并且具有重大的科研价值和实用价值。
3.目前世界上已知现存人类语言大约7139种,分布在142个不同的语系中,依据人类分辨语言的过程来分析,人类并不需要精通多门语言,便能够对数种语言的种类进行判断。这些有效判断往往需要依赖于某层区分性特征:如韵律特征、基本声学特征、音素特征、词汇和语法等。
4.时序变化信息作为能够描述区分特征的重要依据,其建模方式直接影响语种识别系统的准确率和效率。传统的语种后端建模方式主要有:高斯混合模型
‑
通用背景模型(gmm
‑
ubm)、隐马尔科夫模型(hmm)、广义线性区分
‑
支持向量机模型(glds
‑
svm)等。近年来,基于底层声学特征的深度学习模型方法,得到极大的发展:其对于局部特征的深度抽象能力,可提取更鲁棒的空间特征。但深度神经网络(dnn)、卷积神经网络(cnn)、延时神经网络(tdnn)等作为特征提取器,无法捕捉长时间序列之间的时序依赖关系、导致时序信息丢失。传统循环神经网络(rnn)作为池化编码层,虽然可以有效解决短序列编码问题,但对于长序列却会引发梯度消失和爆炸。长短时记忆网络(lstm/bilstm)虽然可以有效缓解这一问题,但现有的时序方法只能够获取时序末端的隐藏层编码,不可避免地忽略了隐藏层之间重要的时序信息。
5.针对以上的问题,提出基于层叠双向时序池化的语种识别方法,该方法可高效、准确地编码隐藏层序列的时序特征,从而获取音频的高阶动态信息,降低语种识别系统的错误率。
技术实现要素:
6.本发明的目的是为了解决语音信号的时序动态编码问题,并降低语种识别系统的错误率,进而提出了一种基于层叠双向时序池化的语种识别方法。
7.本发明为解决上述技术问题采取的技术方案是:一种基于层叠双向时序池化的语种识别方法,该方法包括以下步骤:
8.步骤1、对训练集与验证集中所有语音进行预处理并提取梅尔频率倒谱系数(mfcc)和基音(pitch)参数,作为前端特征。
9.步骤2、将步骤1对应的训练集和验证集的前端特征,截取成长度相同的段级特征,作为残差
‑
双向长短时记忆神经网络的训练样本和验证样本数据集合。
10.步骤3、用步骤2中的训练样本数据集的段级特征批量训练残差
‑
双向长短时记忆
神经网络,然后将训练得到的神经网络作为高层时序特征提取器,提取高层时序特征前向表示与后向表示
11.步骤4、将步骤3得到的高层时序特征,经过非线性特征映射后,作为双向时序池化的输入,得到层叠双向时序池化特征。
12.步骤5、将步骤4的层叠双向时序池化特征,经特征正则化后,由逻辑回归(lr)分类器进行评分。
13.进一步地,步骤1中所述的梅尔频率倒谱系数的计算步骤分别是分帧、预处理、短时傅里叶变换、频谱平方、能量谱梅尔滤波、对数运算、离散余弦。
14.步骤1中所述的基音参数的计算步骤分别为,首先对于音频文件下采样,再对下采样的音频计算归一化互相关系数函数,对相关处最大值进行记录、在上述最大值处选取候选点集合、在候选点集合中使用动态规划算法选取最佳候选点。
15.进一步地,步骤2中所述对训练数据集切割为固定长度的片段,对一句语音的前端特征,按任务最短语音段长度要求,按照其窗长和帧移设置切割成对应的长度。不足此长度的帧的语音段则丢弃。
16.进一步地,步骤3中所述对残差
‑
双向长短时记忆神经网络的训练步骤分为,用步骤2中切割完成的特征训练神经网络,并保存网络参数,作为提取高层时序特征的网络参数;
17.步骤3中所述提取高层时序特征,具体步骤为:将训练集、测试集和注册集分别经过训练好的残差
‑
双向长短时记忆神经网络,得到高层时序特征。
18.进一步地,步骤4中所述非线性变换定义为:
[0019][0020]
其对应海林格核函数为:
[0021][0022]
其中x
+
,x
‑
,y
+
,若x
i
≥0,则x
i+
=x
i
,否则x
i
=0。若x
i
<0,则x
i
‑
=
‑
x
i
,否则x
i
=0。y
+
、y
‑
亦是。且
[0023]
步骤4中所述双向时序池化包含前、后向时序池化,经前向、后向时序池化后的特征u均满足以下约束:
[0024][0025]
其中为在t
i
,t
j
时刻的h
f
或h
b
序列中元素的非线性时序特征。
[0026]
式(3)中的线性参数u可由以下逐点排序学习定义:
[0027][0028]
则前向、后向时序池化均可定义为l2
‑
loss支持向量回归形式:
[0029][0030]
其中[
·
]
≥0
=max{0,
·
},ε为不敏感系数,c为正则项系数。
[0031]
为求解式(5),等价于解决如下对偶问题:
[0032][0033]
其中:
[0034][0035]
上式为核矩阵,q中元素其中t
i
,t
j
=1,...,t。
[0036]
对式(6)中α
+
,α
‑
进行组合,可以得到以下二次规划形式:
[0037][0038]
其中i为单位矩阵,t=[1,2,...,t]
t
为时序向量。
[0039]
求解式(8)得到单向时序池化特征u为:
[0040][0041]
且在最优处满足
[0042]
定义层叠双向时序池化特征:
[0043][0044]
其中u
f
为前向时序池化特征,u
b
为后向时序池化特征。
[0045]
具体地:
[0046][0047][0048]
其中t=1,...,t对应于残差网络输出特征的时序顺序。
附图说明
[0049]
图1:本发明流程图。
[0050]
图2、图3、图4和图5:不同正则项系数(c)对应任务的平均损失(cavg)、等错误率(eer)的对比图。
具体实施方式
[0051]
下面将通过实施例并结合附图,对本发明中的技术方案进行详细清楚的描述,所描述的实施特例仅是本发明的一部分实施例。
[0052]
实施例:
[0053]
本发明采取的技术方案是一种基于层叠双向时序池化的语种识别方法,该方法包括以下步骤:
[0054]
步骤1、对训练集与验证集中所有语音进行预处理并提取梅尔频率倒谱系数(mfcc)和基音(pitch)参数,作为前端特征。
[0055]
步骤2、将步骤1对应的训练集和验证集的前端特征,截取成长度相同的段级特征,作为残差
‑
双向长短时记忆神经网络的训练样本和验证样本数据集合。
[0056]
步骤3、用步骤2中的训练样本数据集的段级特征批量训练残差
‑
双向长短时记忆神经网络,然后用训练完成的神经网络作为高层时序特征提取器,提取高层时序特征表示与其中与残差网络特征x=[x1,x2,...,x
t
]中序列的起始特征x1相对应。
[0057]
步骤4、将步骤3得到的高层时序特征,经过非线性变换后,作为双向时序池化的输入,对应得到层叠双向时序池化特征。
[0058]
步骤5、将步骤4的层叠双向时序池化特征,经特征正则化后,由逻辑回归(lr)分类器进行评分。
[0059]
在本实施例中,所述步骤1的具体过程为:
[0060]
步骤1
‑
1、对输入的语音信号,进行预加重、分帧、加窗、傅里叶变换、幅值平方、梅尔滤波、对数功率再经离散余弦变换得到梅尔倒谱系数,其中,音频采样率为16000hz,窗长25ms,帧移10ms。
[0061]
步骤1
‑
2、再对语音信号计算基音系数叠加到梅尔倒谱系数特征上,首先对音频下采样、计算相关关系、对相关处最大值进行记录、选取候选点集合、在集合内选取最佳点,从而得到基音系数。
[0062]
在本实施例中,所述步骤2的具体过程为:
[0063]
将训练数据集切割为长度为100的片段,对一句语音的前端特征,不足此长度的语音段则丢弃。
[0064]
在本实施例中,所述步骤3的具体过程为:
[0065]
步骤3
‑
1、将步骤2处理后的训练集的等长语音段作为残差
‑
双向长短时记忆神经网络的输入,训练神经网络。残差神经网络为resnet
‑
50,池化操作为最大池化,激活函数选为relu。双向长短时记忆网络为单层。
[0066]
步骤3
‑
2、将步骤1的训练集数据,经过步骤3的高层特征提取器,得到训练集的p=768维高层时序特征序列
[0067]
在本实施例中,所述步骤4的具体过程为:
[0068]
将步骤3得到的高层时序特征经非线性变换后,得到非线性特征序列其作为双向时序池化的输入,得到层叠双向时序池化特征
[0069]
在本实施例中,所述步骤5的具体过程为:
[0070]
将步骤4的双向时序池化特征,经均值正则化(sub
‑
mean)和长度正则化(l
‑
norm)后,由逻辑回归(lr)分类器进行评分。
[0071]
实验结果:
[0072]
本发明采用东方语种识别大赛(olr
‑
2019)数据集中的任务2与任务3进行性能验证,性能评价方式采用平均损失(cavg)、等错误率(eer)。
[0073]
不同非线性变换对本发明(resnet
‑
bilstm rank)的性能影响如表1所示,实验结果表明,海林格核函数使双向时序池化获得非线性建模能力,能提取更鲁棒的时序特征。
[0074]
对比其他方法,本发明使系统的平均损失、等错误率明显降低,如表2所示,相较于基线系统,本发明使任务2的相对平均损失、相对等错误率分别降低22.93%、25.36%。使任务3的相对平均损失、相对等错误率分别降低44.54%、48.68%。相较于双向长短时记忆网络(bilstm)方法、相对平均损失、相对等错误率分别降低8.75%、8.69%、13.73%、13.78%。
[0075]
表1:海林格核函数与等价核函数对不同任务的平均损失、等错误率对比表。
[0076]
表1
[0077][0078]
表2:在olr
‑
2019数据库上本发明方法(命名resnet
‑
bilstm rank)与其他方法的平均损失(cavg)、等错误率(eer)对比表。
[0079]
表2
[0080][0081]
以上实施例仅用于说明本发明的设计思想和特点,其目的在于使本领域内的技术人员能够了解本发明的内容并据以实施,本发明的保护范围不限于上述实施例。因此,凡依据本发明所揭示的原理、思路所作的等同变化,仍属于本发明的保护范围之内。