1.本发明涉及多智能体集群间的协同与博弈对抗控制领域,尤其是涉及一种拒止环境下基于粒子群算法的群体机器人控制方法。
背景技术:
2.随着智能无人技术的快速发展和成熟应用,无人设备间的协同作战已经成为可能,无人集群间的协同攻防对抗逐渐成为未来战争的重要模态。作为多智能体技术的应用载体,无人集群通过感知环境,判断周围态势,依据一定的攻防策略,采取集火攻击、伤兵回撤、障碍避让、群体避碰、分散、集中、协作、援助等行为,实现攻防对抗。
3.群体机器人的协同攻防对抗可以描述为复杂多约束条件下的最优决策问题,最经典的是疆土守卫问题。在此问题中,对抗环境由入侵方和防守方两个多智能群体组成。其中,入侵方目的是试图尽可能的靠近并进入某一领土,防守方的目的是拦截入侵方使其尽可能的远离该领土。对抗环境下态势的优劣取决于入侵者、防守者和领土三者之间的关系,由于多智能体攻防对抗任务状态空间维数高,策略求解空间随实体对象规模的增加呈指数级增大,态势复杂且变化快,攻防策略多样,导致求解的难度大,需要高效的决策算法。
4.目前最流行的群体对抗方法是多智能体深度强化学习方法。然而此类算法需要大量的预训练、受限于维数灾难问题,且依赖精确的全球定位和通信,无法在拒止环境中实现有效协作和对抗。
技术实现要素:
5.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种拒止环境下基于粒子群算法的群体机器人控制方法,该控制方法弥补了当前大多数多智能体算法以来全局定位和通信,受限于维数灾难的瓶颈问题。
6.本发明的目的可以通过以下技术方案来实现:
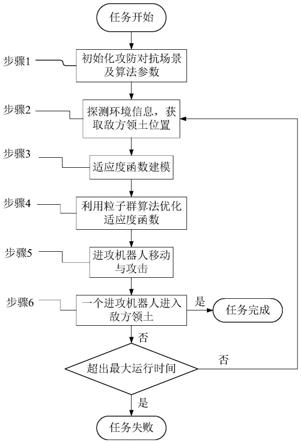
7.本发明提供了一种拒止环境下基于粒子群算法的群体机器人控制方法,该方法包括以下步骤:
8.步骤1、建立拒止环境下的攻防对抗场景,并初始化粒子群算法的参数;
9.步骤2、进攻机器人通过传感器探测周围环境信息,获取友方机器人和敌方机器人的态势信息,并利用惯性导航技术实时计算敌方领土的位置
10.步骤3、所述进攻机器人利用探测到的周围环境信息构建包含敌军机器人状态信息、友军机器人状态信息和敌方领土信息的适应度函数;
11.步骤4、利用粒子群算法优化所述适应度函数,得到所述进攻机器人的最优占位,并指导所述进攻机器人在下一时间片的移动与攻击;
12.步骤5、所述进攻机器人进行移动与攻击操作;
13.步骤6、如果存在一个进攻机器人进入敌方领土,则任务完成;否则判断是否达到最大运行时间,如果是,则任务失败;否则转到步骤2进行下一时间片的迭代。
14.优选地,所述步骤1中建立拒止环境下的攻防对抗场景,并初始化粒子群算法的参数,具体为:初始化n个进攻机器人的位置、m个防守机器人的位置以及敌方领土的gps定位坐标u;初始化粒子群算法中的粒子初始个数加速因子c1与c2,惯性权重w和问题的维度d;
15.所有机器人的属性相同,均具备p点血量,当机器人受到攻击时血量减p,当机器人血量小于等于0时,即该机器人被消灭。
16.优选地,所述步骤2具体为:每个进攻机器人根据自己的位置和移动方向构建坐标系;通过传感器探测周围环境信息,获取友方机器人和敌方机器人的坐标,并利用惯性导航技术实时计算敌方领土的位置
17.优选地,所述步骤3中所述进攻机器人利用探测到的周围环境信息构建进攻机器人的适应度函数,具体为:进攻机器人ai根据敌军机器人状态信息、友军机器人状态信息和敌方领土信息构建适应度函数fi,其表达式为:
18.fi=f1+f2+f319.其中,f1是根据敌军机器人状态信息构建的对抗适应度,f2是根据友军机器人状态信息构建的协作适应度,f3是敌方领土适应度。
20.优选地,所述对抗适应度函f1的表达式为:
[0021][0022]
其中ψ是攻击机器人ai邻域范围r1内所有敌方机器人的索引,是根据第k个敌方机器人状态信息生成的子适应度函数;是第k个敌方机器人的坐标;x=(x1,x2)是自变量,表示进攻机器人的直角坐标系中某个位置的坐标;σ1和w1分别定义了类高斯模型的宽度和幅度;s(i,k)是衡量第i个攻击机器人ai的态势是否优于敌方机器人bk的指标,决定了攻击机器人ai是向敌方机器人bk移动还是后退,其表达式为:
[0023][0024]
所述机器人的态势信息是根据友方机器人的数量和总血量计算得到,其中
“‑
1”和“1”分别代表攻击机器人ai处于不利和有利态势;ni和分别表示攻击机器人ai攻击范围r0内的所有友方机器人的数量和总血量值;mk和分别是敌方机器人bk攻击范围r0内的所有敌方机器人数量和总血量值;
[0025]
当s(i,k)=-1时,f
bk
是一个山谷形函数,表示攻击机器人ai离敌方机器人bk越远,攻击机器人ai的适应度越高;
[0026]
当s(i,k)=1时,f
bk
是一个山峰形函数,表示攻击机器人ai与敌方机器人bk越接近,攻击机器人ai的适应度越高。
[0027]
优选地,所述进攻机器人ai的协作适应度函数f2的表达式为:
[0028][0029]
其中φ是攻击机器人ai邻域范围r1内中所有友军的索引;f
ak
是根据第k个进攻机器人状态信息生成的子适应度函数,其中是第k个攻击者的坐标;x=(x1,x2)是自变量,表示进攻机器人的直角坐标系中某个位置的坐标;σ2和w2分别定义了类高斯模型的宽度和幅度;
[0030]
如果进攻机器人ai在τ个时间片内,面对周围的敌方机器人一直处于劣势,则进攻机器人ai需要摆脱其同伴的约束并退出群体,此时将协作适应度函数f2设置为0,进攻机器人ai独立行动来搜索更好的攻击位置;
[0031]
当ai与其友军ak之间的距离小于预设阈值δ=10|ψ|时,f
ak
设置为0,以避免两个进攻机器人发生碰撞。
[0032]
优选地,所述攻机器人ai的敌方领土适应度f3表达式为:
[0033][0034]
其中u=(u1,u2)是敌方领土中心位置的坐标,x=(x1,x2)是自变量,表示进攻机器人的直角坐标系中某个位置的坐标;σ3和w3分别定义了类高斯模型的宽度和幅度。
[0035]
优选地,所述步骤4具体为:在每个时间片中,执行粒子群算法优化所述适应度函数,得到进攻机器人ai在其当前情况下的最佳位置pg;所述粒子群算法的搜索空间为以进攻机器人ai的坐标为中心,r1为半径的圆形区域内。
[0036]
优选地,所述适应度函数的速度和位置更新表达式为:
[0037][0038][0039]
其中,c1,c2是常数加速因子,w是惯性权重,表示第i个粒子在第d维的速度,d∈[1,...,d],表示第i个粒子在第d维的位置,和是随机数向量;d是环境的维度,对于二维对抗环境d=2,三维对抗环境d=3。
[0040]
优选地,所述步骤4具体为:
[0041]
每个攻击机器人向计算得到的最优位置pg方向移动,如果该机器人与最优位置pg的距离小于一个时间片内攻击机器人移动的最大距离则攻击机器人移动到最优位置pg;否则,向最优位置pg方向移动距离;在机器人移动过程中,如果其下一时间片所处位置的警戒区域中存在其它机器人则将其移动方向逆时针旋转a度,当旋转次数超过预设次数之后,如果机器人仍然无法找到合适的无碰撞路径,则停留在当前位置,直到下一个时间片;
[0042]
如果攻击机器人在移动过程中有敌军进入其攻击范围,则选择距离其最近的敌军攻击;如果攻击机器人的态势优于敌方机器人,其会向敌方机器人移动并发起攻击,即攻击机器人离敌方机器人越近,其适应度越高;相反,如果攻击机器人的态势劣于敌方机器人,
则其距离敌方机器人越近,其适应度越低;
[0043]
进攻机器人和其友军处于协作关系并组成一个小组来攻击敌方机器人群,进攻机器人距离其友军越近,其适应度就越高。
[0044]
与现有技术相比,本发明具有以下优点:
[0045]
1)本发明中群体机器人利用自身携带的传感器感知周围环境来自身的运动,不依赖全局导航系统;每个机器人构建各自的坐标系,通过获取周围智能体的相对坐标实现协同与对抗,不依赖全局定位系统;
[0046]
2)本发明中机器人的适应度函数融合了友方、敌方和敌方领土的信息,实现了机器人在协同与对抗环境的控制;
[0047]
3)与强化学习方法相比,本发明采用的基于粒子群算法的群体机器人分布式控制具备无需预训练、可扩展性强的优势。
附图说明
[0048]
图1为拒止环境下基于粒子群算法的群体机器人控制方法流程图。
[0049]
图2为进攻机器人的直角坐标系示例图;
[0050]
图3为进攻机器人a1的适应度模型示例;
具体实施方式
[0051]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
[0052]
本实施例提供了一种拒止环境下基于粒子群算法的群体机器人进攻方法,如图1所示,包括以下步骤:
[0053]
步骤1、建立拒止环境下的攻防对抗场景,设置n个进攻群体机器人的位置、m个防守群体机器人的位置、敌方领土的位置坐标,设所有机器人属性相同,具备10点血量,当机器人受到攻击时血量减1,当机器人血量小于等于0时,即该机器人被消灭;初始化粒子群算法的粒子初始个数加速因子c1与c2,惯性权重w以及问题的维度d;所有机器人的属性相同,均具备10点血量,当机器人受到攻击时血量减1,当机器人血量小于等于0时,即该机器人被消灭。
[0054]
步骤2、进攻机器人通过传感器探测周围环境,获取友方机器人和敌方机器人的态势信息,并利用惯性导航技术实时计算敌方领土的位置
[0055]
步骤3、所述进攻机器人利用探测到的周围环境信息构建包含敌军机器人状态信息、友军机器人状态信息和敌方领土信息的适应度函数;
[0056]
如图2所示,每个进攻机器人ai以自己的位置为坐标原点,以移动方向为横轴的正方向,构建自己的直角坐标系;其中qj、pk和u分别是第j个防御者、第k个攻击者和领土的坐标,进攻机器人ai通过使用其传感器感知环境来获得qj和pk;
[0057]
每个进攻机器人在初始化位置时已知敌方领土的坐标u,在机器人移动过程中应
用惯性导航技术实时计算敌方领土的大致坐标
[0058]
对于每个进攻机器人,其适应度函数包括三部分信息:敌军机器人的状态信息、友军机器人的状态信息和敌方领土信息;
[0059]
所述进攻机器人ai的适应度函数fi的计算公式为:
[0060]fi
=f1+f2+f3[0061]
其中,f1是根据敌军机器人状态信息构建的对抗适应度,f2是根据友军机器人状态信息构建的协作适应度,f3是敌方领土适应度。
[0062]
1)构建攻击机器人的对抗适应度函数f1[0063]
如果攻击机器人的态势优于敌方机器人,其会向敌方机器人移动并发起攻击。将这种情况映射到适应度函数模型中,即攻击机器人离敌方机器人越近,其适应度越高。相反,如果攻击机器人的态势劣于敌方机器人,则其距离敌方机器人越近,其适应度越低。利用类高斯分布来构建此对抗适应度函数模型。攻击机器人的对抗适应度函数f1为:
[0064][0065]
其中ψ是攻击机器人ai邻域范围r1内所有敌方机器人的索引f
bk
是根据第k个敌方机器人状态信息生成的子适应度函数。是第k个敌方机器人的坐标;x=(x1,x2)是自变量,表示直角坐标系中某个位置的坐标;σ1和w1分别定义了类高斯模型的宽度和幅度。
[0066][0067]
s(i,k)是衡量第i个攻击机器人ai的态势是否优于敌方机器人bk的指标。机器人的态势是根据其友军的数量和总血量计算得到,其中
“‑
1”和“1”分别代表ai处于不利和有利态势;ni和是ai攻击范围r0内的攻击机器人(包括攻击者ai)的数量和总血量值;mk和分别是bk攻击范围r0内的敌方机器人数量和总血量值。当s(i,k)=-1时,f
bk
是一个山谷形函数。这意味着ai离bk越远,ai的适应度越高。当s(i,k)=1时,f
bk
是一个山峰形函数。这意味着ai与bk越接近,ai的适应度越高。s(i,k)决定了ai是向bk移动还是后退。
[0068]
2)构建进攻机器人ai的协作适应度函数f2[0069]
进攻机器人和其友军处于协作关系并组成一个小组来攻击敌方机器人群。将这种情况映射到适应度函数模型中,即进攻机器人距离其友军越近,它的适应度就越高。进攻机器人ai的协作适应度函数f2为:
[0070][0071]
其中φ是ai邻域范围r1内中所有友军的索引。f
ak
是根据第k个进攻机器人状态信息生成的子适应度函数,其中是第k个攻击者的坐标。值得注意的是,根据f2,攻击机器人群体会动态地形成小组。如果ai在τ个时间片内,面对周围的敌方机器人一直
处于劣势,则ai需要摆脱其同伴的约束并退出群体,此时将f2设置为0,ai独立行动来搜索更好的攻击位置。当ai与其友军ak之间的距离小于阈值δ=10|ψ|时,f
ak
设置为0以避免两个进攻机器人发生碰撞。
[0072]
3)根据敌方领土的位置信息构建适应度函数f3[0073]
由于进攻机器人的目标是进入敌方领土,其距离敌方领土越近,适应度越高。因此,适应度函数f3为:
[0074][0075]
其中u=(u1,u2)是敌方领土中心位置的坐标。
[0076]
图3是进攻机器人a1的适应度模型示例,其中两个菱形表示a1和a2,三个三角形是敌方机器人b1、b2和b3,星型是敌方领土t。其中a1和a2之间是合作关系,a1和b1、b2和b3之间的关系是对抗性关系。该适应度模型应用到粒子群算法中优化得到拒止环境下的群体机器人攻击策略,以指导进攻机器人的移动与攻击。
[0077]
步骤4、利用粒子群算法优化所述适应度函数,得到该进攻机器人的最优占位,并指导该进攻机器人在下一时间片的移动与攻击;
[0078]
在每个时间片中,执行粒子群算法pso优化进攻机器人ai在其当前情况下的最佳位置pg。由于攻击者的移动距离在一个时间片内是有限的,而且环境是动态变化的,所以它只需要在其邻域r1内找到适应度最好的位置。
[0079]
因此,粒子群算法pso的搜索空间被约束在以进攻机器人ai的坐标为中心,r1为半径的圆形区域内。
[0080]
优化适应度函数的速度和位置更新公式如下:
[0081][0082][0083]
其中,c1,c2是常数加速因子,w是惯性权重,表示第i个粒子在第d维的速度,d∈[1,...,d],表示第i个粒子在第d维的位置,和是随机数向量;d是环境的维度,对于二维对抗环境d=2,三维对抗环境d=3;
[0084]
步骤5、进攻机器人进行移动与攻击操作;
[0085]
每个机器人向计算得到的最优位置pg方向移动,如果该机器人与最优位置pg的距离小于一个时间片内机器人移动的最大距离则机器人移动到最优位置pg;否则向pg方向移动距离。
[0086]
在移动过程中,如果机器人在移动过程中有敌军进入其攻击范围,则选择距离其最近的敌军攻击。在机器人移动过程中如果其下一时间片所处位置的警戒区域中存在其它机器人则将其移动方向逆时针旋转15度,在一系列的旋转之后(23次)如果机器人仍然无法找到合适的无碰撞路径,则停留在当前位置,直到下一个时间片。
[0087]
步骤6、如果存在一个进攻机器人进入敌方领土,则任务完成;否则判断是否达到最大运行时间,如果是,则任务失败;否则转到步骤2进行下一时间片的迭代。
[0088]
为了更直观的验证本发明在群体机器人领土入侵问题中的性能,与以下三个应用于敌方机器人群体的算法进行了对抗实验:
[0089]
(1)基于规则的算法,敌方机器人总是向领土和距离自己最近的进攻机器人的中点位置移动,对进攻机器人进行拦截。
[0090]
(2)dpso攻击任务分配算法,“cooperative multi-task assignment for multiple uavs,”electronics optics&control,vol.24,no.1,pp.46-50,2017.
[0091]
(3)sdpso攻击任务分配算法,“uav cooperation multi-task assignment based on discrete particle swarm optimization algorithm,”computer simulation,vol.35,no.2,pp.22-28,2018.
[0092]
算法的对抗结果如表1所示。
[0093]
表1
[0094][0095][0096]
很明显,当进攻机器人群体和敌方机器人群体的数量相同时,应用pso-as方法的进攻机器人群体获胜率为100%。当进攻机器人群体的数量只有敌方机器人群体的75%时,所提出的方法仍然具有大于50%的获胜成功率。
[0097]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。