一种基于深度学习辅助rls滤波处理的语音增强方法
技术领域
1.本发明属于人工智能技术领域,涉及语音识别,具体涉及一种基于深度学习辅助rls滤波处理的语音增强方法。
背景技术:
2.随着语音交互技术的广泛应用,传统的单麦克风语音增强方法已不能满足交互技术中语音质量的需求。比如在远场环境或嘈杂环境中,单麦克风方法捕获的信息有限,降噪性能受限。此时,采用麦克风阵列信号可有效利用语音信号的方向信息捕获波束内语音信号,抑制其他方向波束的信号,获得更好的降噪效果。
3.广义旁瓣相消(general sidelobe canceller, gsc)方法作为经典的波束形成算法之一,得以广泛应用。但是,由于麦克风阵列语音信号中的多路径传播会导致gsc在阻塞语音信号、计算噪声参考时产生语音泄漏,且语音信号指向性误差会导致捕获的语音波束信号中噪声残留成分增加。若一味的消除固定波束形成信号中的残留噪声,忽略语音泄漏的存在,将会导致较为严重的语音失真,然而若忽略固定波束形成信号中大噪声的残留,又将会严重降低信号质量。
技术实现要素:
4.为克服现有技术存在的缺陷,本发明公开了一种基于深度学习辅助rls滤波处理的语音增强方法,该方法有效减少了麦克风波束信号处理的算力,可在不增加失真的情况下减少输出信号中的噪声残留,增强语音信号,从而提升语音识别率。
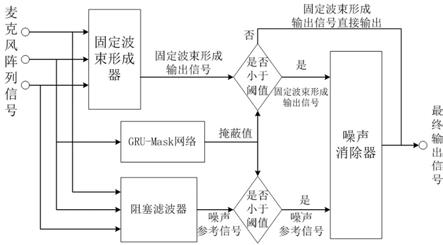
5.本发明所述基于深度学习辅助rls滤波处理的语音增强方法,包括如下步骤:s1.采用广义旁瓣相消的波束形成方法对麦克风阵列语音信号y(l,k)进行处理,得到固定波束形成输出信号y
s
(l,k)和噪声参考信号u(l,k);l,k分别表示时间和频率索引;s2.随机提取麦克风阵列中任意一路麦克风信号的特征信号送入gru
‑
mask网络计算出原始麦克风信号的掩蔽值mask(l,k) ;s3.将gru
‑
mask网络输出的掩蔽值mask(l,k)与噪声阈值thred进行比较:当mask(l,k)<thred时,生成噪声消除器w0(l,k)对固定波束形成输出信号y
s
(l,k)做滤波处理,处理后的信号作为最终输出信号,否则以固定波束形成输出信号y
s
(l,k)作为最终输出信号。
6.优选的,所述噪声消除器w0(l,k)根据固定波束形成输出信号y
s
(l,k)和噪声估计信号u(l,k),采用rls算法计算,具体如下:
其中,u或ф的上标
‑
1、h、*分别表示逆、转置和共轭转置操作;初始化操作ф
‑1(0,k)=i,w0(0,k)= k(0,k)=o
(m
‑
1)*1
,其中o表示零矩阵,m为麦克风数量;ф
‑1(l,k), k(l,k)均为中间变量,λ为遗忘因子;滤波后的最终输出信号s(l,k)为:s(l,k)= y
s
(l,k)
‑ꢀ
w0(l,k) * u(l,k) 。
7.优选的,所述gru
‑
mask网络由一个预处理层、一个语音谱估计器、一个噪声谱估计器、一个增益模拟器构成;其中预处理层由1个全连接层构成;语音谱估计器由2个gru层构成;噪声谱估计器由1个gru层构成;增益模拟器由1个gru层和1个全连接层构成本发明利用深度学习的方法计算出信号中信息主导成分,仅对噪声成分主导的信号采用rls算法进行滤波处理,有效减少了麦克风波束信号处理的算力,可实现在不增加失真的情况下减少输出信号中的噪声残留,达到增强语音信号,提升语音识别率和人机交互体验感的目的。
附图说明
8.图1为本发明所述语音增强方法的一个具体流程示意图;图2为一个具体实施方式中,采用传统gsc方法与本发明处理的频谱对比图;图2中横坐标为时间,纵坐标为频率;图2中(a1)部分为传统gsc方法处理的频谱图,(a2)部分为本方法处理的频谱图;图3为一个具体实施方式中,采用传统gsc方法与本发明处理的波形对比图;图3中横坐标为时间,纵坐标为电压振幅; 图3中(a3)部分为传统gsc方法处理的波形图, (a4)部分为本方法处理的波形图。
具体实施方式
9.下面对本发明的具体实施方式作进一步的详细说明。
10.本发明所述基于深度学习辅助rls滤波处理的语音增强方法,包括如下步骤:s1.采用广义旁瓣相消的波束形成方法对麦克风阵列语音信号y(l,k)进行处理,得到固定波束形成输出信号y
s
(l,k)和噪声参考信号u(l,k);l,k分别表示时间和频率索引;s2.随机提取麦克风阵列中任意一路麦克风信号的特征信号送入gru
‑
mask网络计算出原始麦克风信号的掩蔽值mask(l,k) ;s3.将gru
‑
mask网络输出的掩蔽值mask(l,k)与噪声阈值thred进行比较:
当mask(l,k)<thred时,生成噪声消除器w0(l,k)对固定波束形成输出信号y
s
(l,k)做滤波处理,处理后的信号作为最终输出信号,否则以固定波束形成输出信号y
s
(l,k)作为最终输出信号。
11.如图1所示,实施方式中的具体流程如下:s1 采用广义旁瓣相消(gsc)的波束形成方法对语音信号y(l,k)进行处理,得到固定波束形成输出信号y
s
(l,k)和噪声参考信号u(l,k)。
12.l,k分别表示时间和频率索引;广义旁瓣相消(gsc)的波束形成方法通常主要包含固定波束形成器w
bf
(k)、阻塞矩阵b(k)和噪声消除器w0(l,k)三个部分。麦克风语音信号y(l,k)通过固定波束形成器w
bf
(k)模块处理,得到固定波束形成输出信号y
s
(l,k),如下:y
s
(l,k)= w
bf
(k)* y(l,k),麦克风语音信号y(l,k)通过阻塞矩阵b(k)去掉麦克风语音信号y(l,k)中有用的语音信号,得到噪声参考信号u(l,k),如下:u(l,k)= b(k) *y(l,k)。
13.s2随机提取麦克风阵列中任意一路麦克风信号的特征信号送入gru
‑
mask网络计算出原始麦克风信号的mask(l,k)。其中,gru
‑
mask网络的输入为麦克风信号的特征信号,输出信号为mask(l,k),该mask(l,k)表征该路麦克风信号中的主导成分为语音信号还是噪声信号,为后续是否做进一步的滤波处理提供判据。
14.gru
‑
mask网络由一个预处理层、一个语音谱估计器、一个噪声谱估计器、一个增益模拟器构成。其中预处理层由1个全连接层构成;语音谱估计器由2个gru层构成;噪声谱估计器由1个gru层构成;增益模拟器由1个gru(门控循环单元)层和1个全连接层构成。
15.其中输入信号维度为m,即预处理层维度,语音谱估计器的2个gru层维度分别为g1、g2,噪声谱估计器的gru层维度为g3,增益模拟器的gru层和全连接层维度分别为g4和n。
16.s3将gru
‑
mask网络输出的掩蔽值mask(l,k)与噪声阈值thred进行比较:当mask(l,k)<thred时,生成噪声消除器w0(l,k)对固定波束形成输出信号y
s
(l,k)做滤波处理,处理后的信号作为最终输出信号,否则以固定波束形成输出信号y
s
(l,k)作为最终输出信号。
17.传统gsc方法是波束处理后直接做噪声消除处理,根据gsc波束形成方法,利用固定波束形成输出信号y
s
(l,k)和噪声参考信号u(l,k)设计理想的噪声消除器w0(l,k),用于估计固定波束形成输出信号y
s
(l,k)中残留的噪声并抵消固定波束形成输出信号y
s
(l,k)中的这部分残留噪声。
18.由于多径效应引起语音泄露导致噪声消除器w0(l,k)在消除固定波束形成输出信号y
s
(l,k)中的残留噪声时会消除部分语音,从而引起信号的失真。本发明采用gru
‑
mask网络计算出掩蔽值mask(l,k),将其与预先设定的噪声阈值thred进行比较,作为是否采用噪声消除器w0(l,k)消除残留噪声的依据。
19.当mask(l,k)≥thred时,表明该信号主要由语音成分主导,可忽略掉固定波束形成输出信号y
s
(l,k)中的残留噪声,不必计算噪声消除器w0(l,k)进行抵消。当mask(l,k)<thred时,表明该信号主要由噪声成分主导,此时会增加固定波束形成中的指向性误差,导致固定波束形成输出信号y
s
(l,k)中残余噪声更多,因此需要计算出噪声消除器w0(l,k)去
抵消固定波束形成输出信号y
s
(l,k)中的残余噪声。
20.噪声消除器w0(l,k)根据固定波束形成输出信号y
s
(l,k)和噪声估计信号u(l,k),采用rls(递归最小二乘)算法计算,具体如下:其中,u或ф的上标
‑
1、h、*分别表示逆、转置和共轭转置操作;初始化操作ф
‑1(0,k)=i,w0(0,k)= k(0,k)=o
(m
‑
1)*1
,其中o表示零矩阵,m为麦克风数量,λ为遗忘因子;λ取值范围为小于等于1的正数。
21.本方法仅对原始信号中噪声成分主导的部分固定波束形成输出信号y
s
(l,k)计算噪声消除器w0(l,k)进行滤波处理,滤波后的最终输出信号s(l,k)为:s(l,k)= y
s
(l,k)
‑ꢀ
w0(l,k) * u(l,k)对原始信号中语音成分主导的部分固定波束形成输出信号y
s
(l,k)不做滤波处理,最终输出信号s(l,k)为:s(l,k)= y
s
(l,k)继而也不必计算噪声消除器w0(l,k),可减少算力,更有利于信号实时处理。如此一来,对原始信号中噪声成分主导的部分固定波束形成输出信号y
s
(l,k)做滤波处理,起到降噪和改善信噪比的作用,对原始信号中语音成分主导的部分固定波束形成输出信号y
s
(l,k)不做滤波处理,可有效降低多径效应带来语音泄露导致最终输出语音信号s(l,k)失真的问题。本方法因此可实现在不增加失真的情况下减少算力和降低输出信号中的噪声残留。
22.图1给出了本发明所述方法的一个具体流程示意图,图2给出了传统gsc方法与本发明所述方法处理的频谱对比图,图2中上方(a1)部分为传统gsc方法处理的频谱图,下方(a2)部分为本方法处理的频谱图,从图2可以看出下方语音信号保留白色部分更多,表明失真更小;图3给出了传统gsc方法与本方法处理的波形对比图,图3上方的(a3)部分为传统gsc方法处理的波形图,下方的(a4)部分为本方法处理的波形图,从图3可以看出下方语音的幅值更大,表明处理效果更好,更有利于后续的语音识别。
23.前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。